目录

本篇文章基于GoLang 1.13.
逃逸分析是GoLang编译器中的一个阶段,它通过分析用户源码,决定哪些变量应该在堆栈上分配,哪些变量应该逃逸到堆中。
静态分析
Go静态地定义了在编译阶段应该被堆或栈分配的内容。当编译(go build)和/或运行(go run)你的代码时,可以通过标志-gcflags="-m "进行分析。下面是一个简单的例子。
package main
import "fmt"
func main() {
num := GenerateRandomNum()
fmt.Println(*num)
}
//go:noinline
func GenerateRandomNum() *int {
tmp := rand.Intn(500)
return &tmp
}
运行逃逸分析,具体命令如下:
F:\hello>go build -gcflags="-m" main.go
# command-line-arguments
.\main.go:15:18: inlining call to rand.Intn
.\main.go:10:13: inlining call to fmt.Println
.\main.go:15:2: moved to heap: tmp
.\main.go:10:14: *num escapes to heap
.\main.go:10:13: []interface {} literal does not escape
<autogenerated>:1: .this does not escape
<autogenerated>:1: .this does not escape
从上面的结果.\main.go:15:2: moved to heap: tmp中我们发现tmp逃逸到了堆中。
静态分析的第一步是生成源码的抽象语法树(具体命令:go build -gcflags="-m -m -m -m -m -W -W" main.go),让GoLang了解在哪里进行了赋值和分配,以及变量的寻址和解引用。
下面是之前代码生成的抽象语法树的一个例子:
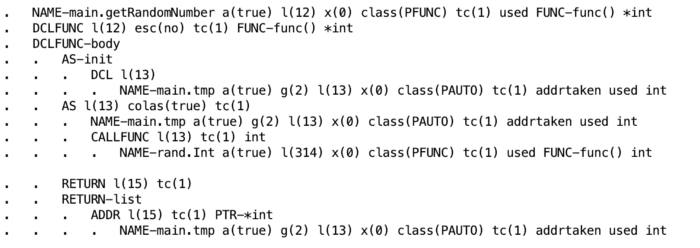
关于抽象语法树请参考: package ast, ast example
为了简化分析, 下面我给出了一个简化版的抽象语法树的结果:

由于该树暴露了定义的变量(用NAME表示)和对指针的操作(用ADDR或DEREF表示),故它可以向GoLang提供进行逃逸分析所需要的所有信息。一旦建立了树,并解析了函数和参数,GoLang现在就可以应用逃逸分析逻辑来查看哪些应该是堆或栈分配的。
超过堆栈框架的生命周期
在运行逃逸分析并从AST图中遍历函数(即: 标记)的同时,Go会寻找那些超过当前栈框架并因此需要进行堆分配的变量。假设没有堆分配,在这个基础上,通过前面例子的栈框架来表示,我们先来定义一下outlive的含义。下面是调用这两个函数时,堆栈向下生长的情况。
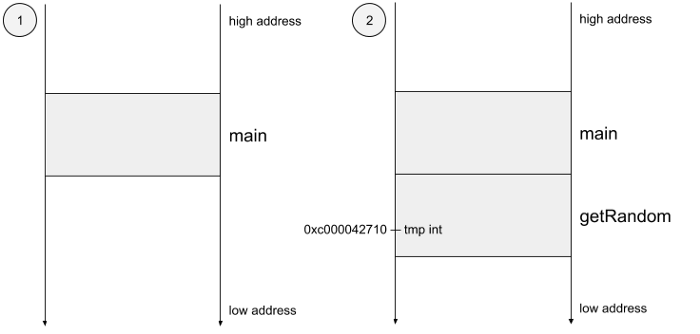
在这种情况下,变量num不能指向之前堆上分配的变量。在这种情况下,Go必须在堆上分配变量,确保它的生命周期超过堆栈框架的生命周期。
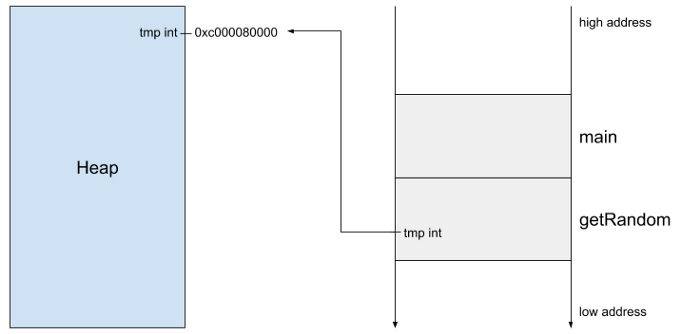
变量tmp现在包含了分配给堆栈的内存地址,可以安全地从一个堆栈框架复制到另一个堆栈框架。然而,并不是只有返回的值才会失效。下面是规则:
- 任何返回的值都会超过函数的生命周期,因为被调用的函数不知道这个值。
- 在循环外声明的变量在循环内的赋值后会失效。如下面的例子:
package main
func main() {
var l *int
for i := 0; i < 10; i++ {
l = new(int)
*l = i
}
println(*l)
}
./main.go:8:10: new(int) escapes to heap
- 在闭包外声明的变量在闭包内的赋值后失效。
package main
func main() {
var l *int
func() {
l = new(int)
*l = 1
}()
println(*l)
}
./main.go:10:3: new(int) escapes to heap
逃逸分析的第二部分包括确定它是如何操作指针的,帮助了解哪些东西可能会留在堆栈上。
寻址和解引用
构建一个表示寻址/引用次数的加权图,可以让Go优化堆栈分配。让我们分析一个例子来了解它是如何工作的:
package main
func main() {
n := getAnyNumber()
println(*n)
}
//go:noinline
func getAnyNumber() *int {
l := new(int)
*l = 42
m := &l
n := &m
o := **n
return o
}
运行逃逸分析表明,分配逃逸到了堆。
./main.go:12:10: new(int) escapes to heap
下面是一个简化版的AST代码:

Go通过建立加权图来定义分配。每一次解引用,在代码中用*表示,或者在节点中用DEREF表示,权重增加1;每一次寻址操作,在代码中用&表示,或者在节点中用ADDR表示,权重减少1。
下面是由逃逸分析定义的序列:
variable o has a weight of 0, o has an edge to n
variable n has a weight of 2, n has an edge to m
variable m has a weight of 1, m has an edge to l
variable l has a weight of 0, l has an edge to new(int)
variable new(int) has a weight of -1
每个变量最后的计数为负数,如果超过了当前的栈帧,就会逃逸到堆中。由于返回的值超过了其函数的堆栈框架,并通过其边缘得到了负数,所以分配逃到了堆上。
构建这个图可以让Go了解哪个变量应该留在栈上(尽管它超过了栈的时间)。下面是另一个基本的例子:
func main() {
num := func1()
println(*num)
}
//go:noinline
func func1() *int {
n1 := func2()
*n1++
return n1
}
//go:noinline
func func2() *int {
n2 := rand.Intn(99)
return &n2
}
./main.go:20:2: moved to heap: n2
变量n1超过了堆栈框架,但它的权重不是负数,因为func1没有在任何地方引用它的地址。 然而,n2会超过栈帧并被取消引用,Go 可以安全地在堆上分配它。