目录
1. 写在前面
本系列文章是对 kubeflow 中的
training-operator模块的代码解析,在写时基于以下代码:
git commit:ab5de23608c4f14a8629cc84d2be55cf2b251f37
Training Operator 管理训练作业的整个生命周期,包括创建作业、监视作业状态、自动扩缩容、处理作业失败等。它确保作业按照用户定义的规范执行,并提供有关作业状态的信息。
简单来说,它在训练任务中提供的主要功能为:
- 在 k8s 集群中创建训练任务的 Pod,Pod 中运行了训练任务的进程
- 配置用作服务发现的信息(如 TF_CONFIG 等环境变量)以及创建相关 k8s 资源(如 Service)
- 监控并更新整个任务的状态
下面从其它角度详细来看一下:
- 从设计目标来看,training-operator 主要有两个:简化训练作业的部署和作业定义标准化。它对训练任务进行了抽象,用户可以容易的使用 k8s 资源定义来描述训练任务的配置,并在 k8s 中方便的完成训练任务的部署与生命周期管理
- 从架构设计来看,training-operator 是 Kubeflow 的一个组件,用于简化和规范在 Kubernetes 上运行训练作业的过程,主要负责管理(TensorFlow、PyTorch 和 MXNet 等)训练作业的生命周期,从定义和配置作业,到监视和维护作业的运行状态
- 从底层实现来看,其是以 Kubernetes 的 Operator 方式实现。对于不同的任务抽象成了不同的 CRD 及与之相关的 controller,其中使用自定义资源定义(CRD)来扩展 Kubernetes API,用声明式的方式定义不同类型的训练任务。用户可以创建自定义资源(例如 TFJob 或 PyTorchJob),其中包含作业的配置信息,例如镜像、资源需求、训练脚本等;controller 负责监视这些自定义资源的变化,并采取相应的操作。当用户创建或更新一个训练作业的自定义资源时,控制器负责解析这些资源,并根据定义的规则在 Kubernetes 集群上启动或更新相应的训练作业
Training Operator 不限于特定的深度学习框架,而是设计为通用的训练作业管理器。它支持多种深度学习框架,如 TensorFlow、PyTorch 等,使得用户能够以一致的方式管理不同框架的训练作业。抽象成 crd 的好处是可以避免用户直接操作底层 k8s 对象。
Training Operator 中的支持的训练框架是以可插拔的方式提供给用户,在进程启动时,可以通过配置参数--enable-scheme选择开启或关闭某些训练框架。在写本文时,共支持以下几种训练框架:TF, PyTorch, Mx, XGBoost, MPI, Paddle。
2. 代码结构
删除部分代码后,可以看到明确的看到代码主要的架构,和其它 golang 项目类似,其项目入口为 cmd/training-operator.v1/main.go
[jeffrey] ~/Documents/training-operator [master]
[16:28:06] ❯ tree
.
├── CHANGELOG.md
├── cmd
│ └── training-operator.v1
│ └── main.go # 项目入口
├── pkg
│ ├── client
│ │ ├── clientset # 定义 k8s client,支持对各类 k8s 资源进行 crud
│ │ │ └── versioned
│ │ │ ├── clientset.go
│ │ │ └── typed
│ │ │ └── kubeflow.org
│ │ │ └── v1
│ │ │ ├── generated_expansion.go
│ │ │ ├── kubeflow.org_client.go
│ │ │ ├── mpijob.go
│ │ │ ├── mxjob.go
│ │ │ ├── paddlejob.go
│ │ │ ├── pytorchjob.go
│ │ │ ├── tfjob.go
│ │ │ └── xgboostjob.go
│ │ ├── informers # 定义不同 crd 的 informer,用于接收对应资源的变更事件
│ │ │ └── externalversions
│ │ │ ├── factory.go
│ │ │ ├── generic.go
│ │ │ ├── internalinterfaces
│ │ │ │ └── factory_interfaces.go
│ │ │ └── kubeflow.org
│ │ │ ├── interface.go
│ │ │ └── v1
│ │ │ ├── interface.go
│ │ │ ├── mpijob.go
│ │ │ ├── mxjob.go
│ │ │ ├── paddlejob.go
│ │ │ ├── pytorchjob.go
│ │ │ ├── tfjob.go
│ │ │ └── xgboostjob.go
│ │ └── listers # 定义不同 crd 的 listert, 用于读取相应的 crd
│ │ └── kubeflow.org
│ │ └── v1
│ │ ├── expansion_generated.go
│ │ ├── mpijob.go
│ │ ├── mxjob.go
│ │ ├── paddlejob.go
│ │ ├── pytorchjob.go
│ │ ├── tfjob.go
│ │ └── xgboostjob.go
│ ├── controller.v1
│ │ ├── control # 提供通用的训练任务生命周期管理的 jobController
│ │ │ ├── controller_ref_manager.go
│ │ │ ├── pod_control.go
│ │ │ ├── podgroup_control.go
│ │ │ ├── service_control.go
│ │ │ └── utils.go
│ │ ├── expectation
│ │ ├── mpi # MPI 训练任务的控制器(内部代码略)
│ │ ├── mxnet # MX 训练任务的控制器(内部代码略)
│ │ ├── paddlepaddle # Paddle 训练任务的控制器(内部代码略)
│ │ ├── pytorch # PyTorch 训练任务的控制器(内部代码略)
│ │ ├── register_controller.go
│ │ ├── register_controller_test.go
│ │ ├── tensorflow # TF 训练任务的控制器
│ │ │ ├── job_test.go
│ │ │ ├── pod_test.go
│ │ │ ├── status_test.go
│ │ │ ├── tensorflow.go
│ │ │ ├── tfjob_controller.go
│ │ │ └── util.go
│ │ └── xgboost # XGBoost 训练任务控制器
2.1 启动流程
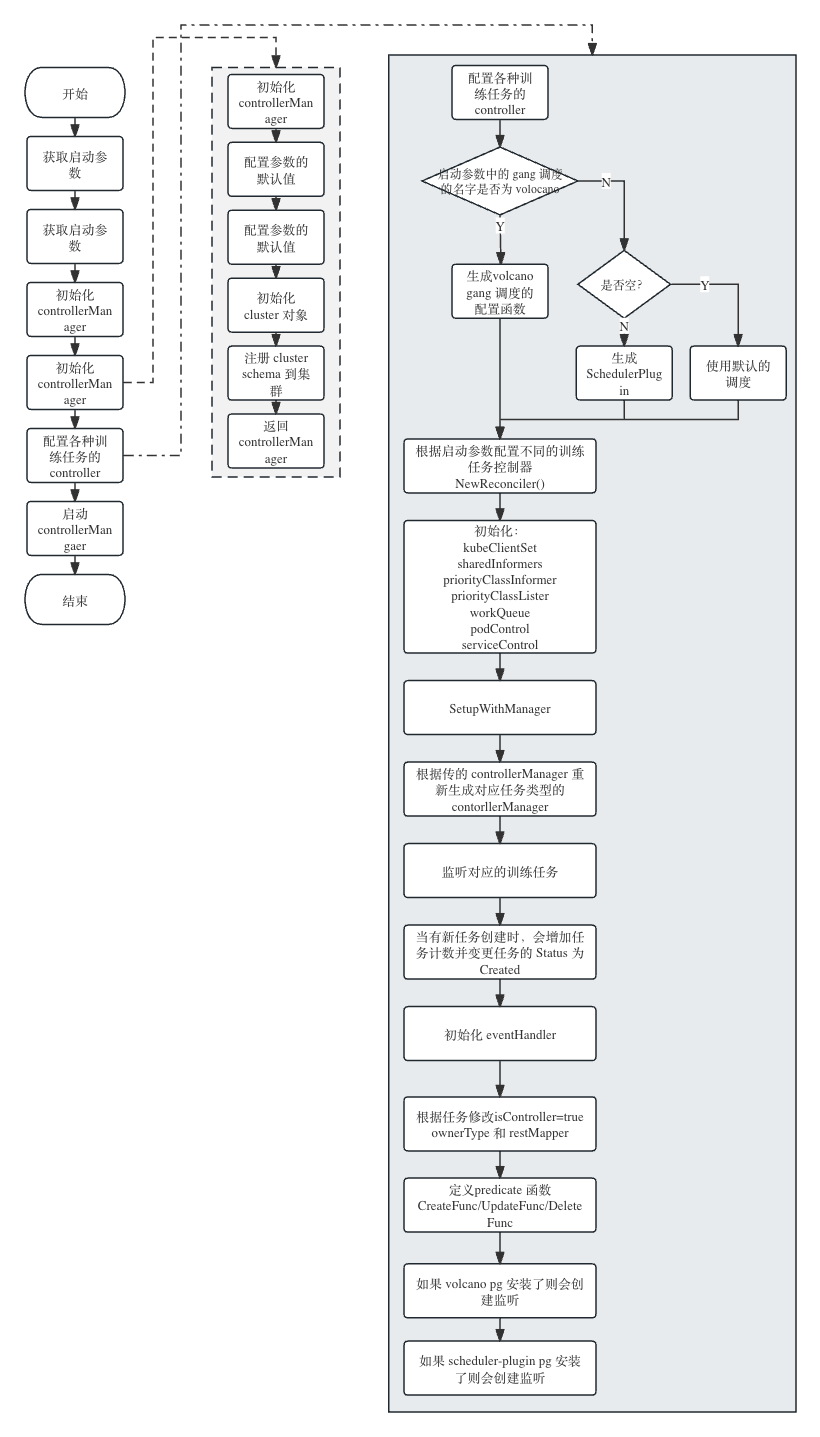
2.2 流程分析
2.2.1 调用 init() 初始化
training-operator 启动时,会先执行代码中的 init() 函数,它的主要作用是把不同的 crd 类型注册到的 Scheme 中,以 MPI 任务为例,如下(其它任务的 init() 函数也可以到以下目录中的其它相应文件中查看)
// pkg/apis/kubelfow.org/v1/mpi_types.go
func init() {
SchemeBuilder.Register(&MPIJob{}, &MPIJobList{})
SchemeBuilder.SchemeBuilder.Register(addMPIJobDefaultingFuncs)
}
Secheme可以类比于 windows 的注册表,就是把用户自定义的资源及原生的工作负载,都注册到 k8s 中,这样做的目的是为了能实现 GVR <-> GVK 的相互转换,从另一个角度看,这也是一种强类型的限定,避免开发者在写代码时出现字段等不匹配的情况。
此处只是以 mpi 任务为例,其它的任务也是类似。除了任务会调用
init()函数外,其它的地方也会有调用,建议使用代码中全局搜索一下func init()
注册完 crd 后,会解析用户在启动进程时传入的参数及配置日志格式。其中,参数中比较重要的是 gang-scheduler-name,不同的名字会生成不同类型的调度配置函数,默认情况下是不生成 gang 的调度,常用的取值为volcano
2.2.2 生成 controller manager
生成一个新的 Manager interface,用于创建控制器(Controllers)。Manager 接口的定义如下:
// ~/go/pkg/mod/sigs.k8s.io/controller-runtime@v0.16.2/pkg/manager/manager.go
// Manager 它会初化一些共享依赖项,如:`Cache`/`clientset`等,如果用户想要创建一个 Controller 时,需要依赖此 Manager
type Manager interface {
// 与集群交互相关的一系列的方法和接口定义
cluster.Cluster
// 将所依赖的项目设置到相应的组件上(即控制器),当 Manager 调用 Start 时,会运行这些组件。
// 根据 Runnable 的实例是否有实现 LeaderElectionRunnable 接口及用户输入,决定是否在选主模式下运行。
Add(Runnable) error
// 当 Manager 参加完选举后会被关闭(无论是否被选为主)
Elected() <-chan struct{}
...
// 启动所有已注册的控制器,并阻塞直到被取消。
// 需要注意的是,如果使用了 LeaderElection,必须在此返回后立即退出,否则需要选主的组件可能会在丢失锁之后继续运行。
Start(ctx context.Context) error
...
}
2.2.3 启动任务控制器
代码位置:
cmd/training-operator.v1/main.go
通过 setupControllers 启动注册的任务控制器,它接收 manager, enabled-schemes, gang-scheduler名称 和 controller线程数 作为参数。
- 记录正在注册controller
- 根据
gang scheduler名称准备gangSchedulingSetupFunc- 如果没有
gang scheduler名字,使用默认的非gang设置函数 - 如果是
Volcano,创建一个Volcano client并生成一个Volcano设置函数 - 否则使用提供的名称生成一个
scheduler plugins设置函数
- 如果没有
- 验证PodGroup CRD对于gang scheduler是否存在
- 检查
enabled schemes是否为空,如果是则填充所有schemes - 遍历
enabled schemes- 获取 scheme 的设置函数
- 如果不支持,记录错误并退出
- 调用配置函数(SupportedSchemeReconciler)创建 controller,传入 manager,gang scheduling 函数 和 线程数
如果任一 controller 配置失败,记录错误并退出,整体目标是基于配置的 schemes 和 gang scheduler 注册和创建 controllers。至此即为任务控制器的启动流程,接下来,那于启动过程中比较关键的函数 SupportedSchemeReconciler 做一下详细说明。
各个控制器的配置函数 SupportedSchemeReconciler 位于 pkg/controller.v1/register_controller.go(定义如下),它会根据启动参数决定加载哪些任务的 Reconciler 函数。
var SupportedSchemeReconciler = map[string]ReconcilerSetupFunc{
kubeflowv1.TFJobKind: func(mgr manager.Manager, gangSchedulingSetupFunc common.GangSchedulingSetupFunc, controllerThreads int) error {
return tensorflowcontroller.NewReconciler(mgr, gangSchedulingSetupFunc).SetupWithManager(mgr, controllerThreads)
},
...
}
下面以 TFJob 为例看一下在具体控制器中的配置流程。实际上每一个的控制器的配置逻辑基本是一致的,简要概括为以下 8 个步骤。
- 创建
XXJobReconciler, XXJobReconciler 的结构如下:
type TFJobReconciler struct {
common.JobController
client.Client
Scheme *runtime.Scheme
recorder record.EventRecorder
apiReader client.Reader
Log logr.Logger
}
初始化 k8s
clientSet,sharedInformers和priorityClassInformer初始化
common.JobContoller。其中JobController的赋值如下:
r.JobController = common.JobController{
Controller: r,
Expectations: expectation.NewControllerExpectations(),
WorkQueue: &util.FakeWorkQueue{},
Recorder: r.recorder,
KubeClientSet: kubeClientSet,
PriorityClassLister: priorityClassInformer.Lister(),
PriorityClassInformerSynced: priorityClassInformer.Informer().HasSynced,
PodControl: control.RealPodControl{KubeClient: kubeClientSet, Recorder: r.recorder},
ServiceControl: control.RealServiceControl{KubeClient: kubeClientSet, Recorder: r.recorder},
}
- 配置
gang-scheduling。volocano类型的 gang scheduling 的配置函数如下:
var GenVolcanoSetupFunc = func(vci volcanoclient.Interface) GangSchedulingSetupFunc {
return func(jc *JobController) {
jc.Config.GangScheduling = GangSchedulerVolcano
jc.PodGroupControl = control.NewVolcanoControl(vci)
}
}
- 创建对
&kubeflowv1.TFJob{}类型资源的监听,当监听到资源的Created事件时,会调用CreateFunc()做以下两件事情- 实现对任务的计数
- 更新任务的状态。如果任务状态是
apiv1.JobFailed则不会更新;如果新状态与当前一致,则不会更新;其它情况更新为任务状态为kubeflowv1.JobCreated
- 创建
eventHandler。最主要的逻辑就是调用了 controller-runtime 中的库函数 EnqueueRequestForOwner 。其中的参数:scheme用于查找对象类型mapper用于将GVK映射到ResourcesownerType是拥有其他对象的主资源的类型opts用于确定特定的所有者是否应该被协调
当在被拥有的对象上发生事件时,
EnqueueRequestForOwner会完成以事情:- 使用
scheme查找拥有对象 - 获取拥有对象的
GroupVersionKind - 使用
mapper获取所有者的Resource - 如果所有者处理程序允许,为所有者入队一个协调
Request
- 使用
- 创建对
pod/service资源事件的监听, 允许在被拥有对象上的事件触发对拥有对象的协调
在本例中,所有者是一个 TFJob,其拥有的 pods/services 上的事件将触发对 TFJob 的协调。
2.2.4 启动 controllerManager
调用 mgr.Start() 启动所有已注册的 controllers,此处正常情况下不会退出,除非程序出错了或手动 kill 掉。Start() 函数定义的路径在 ~/go/pkg/mod/sigs.k8s.io/controller-runtime@v0.16.2/pkg/manager/manager.go,其内部逻辑如下:
- 添加 Runnable 实例 cluster.Cluster
err := cm.add(cm.cluster); - 根据参数决定是否启用 metricServer/healthProbeServer/pprofServer
- 启动 httpServer 及 webhookServer
httpServer/webhookServer 启动时调用的 Start() 函数如下:
// ~/go/pkg/mod/sigs.k8s.io/controller-runtime@v0.16.2/pkg/manager/runnable_group.go
func (r *runnableGroup) Start(ctx context.Context) error {
var retErr error
...
r.startOnce.Do(func() {
// Start the internal reconciler.
go r.reconcile()
})
...
return retErr
}
func (r *runnableGroup) reconcile() {
for runnable := range r.ch {
...
// Start the runnable.
if err := rn.Start(r.ctx); err != nil {
r.errChan <- err
}
}(runnable)
}
...
}
进而调用 Controller 结构体中的 Start 方法:
// ~/go/pkg/mod/sigs.k8s.io/controller-runtime@v0.16.2/pkg/manager/runnable_group.go
// Start implements controller.Controller.
func (c *Controller) Start(ctx context.Context) error {
...
err := func() error {
...
for i := 0; i < c.MaxConcurrentReconciles; i++ {
go func() {
defer wg.Done()
// Run a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the reconcileHandler is never invoked concurrently with the same object.
for c.processNextWorkItem(ctx) {
}
}()
}
c.Started = true
return nil
}()
...
return nil
}
func (c *Controller) processNextWorkItem(ctx context.Context) bool {
obj, shutdown := c.Queue.Get() // 从队列中取出 key
...
c.reconcileHandler(ctx, obj) // 调谐函数
return true
}
func (c *Controller) reconcileHandler(ctx context.Context, obj interface{}) {
...
result, err := c.Reconcile(ctx, req) // 调用不同任务的类型的调谐函数,不同类型任务的实现方式可以参考下面的方式查看。
...
}
可以在代码中全局搜索一下,能够比较方便的看到每一种类型的训练任务都会实现了 Reconciler
[ ][jeffrey] ~/Documents/training-operator [ master][ v1.21.5]
[17:58:36] ❯ grep -ri "Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) " ./
pkg/controller.v1/mpi/mpijob_controller.go
127: func (jc *MPIJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
pkg/controller.v1/mxnet/mxjob_controller.go
114: func (r *MXJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
pkg/controller.v1/paddlepaddle/paddlepaddle_controller.go
123: func (r *PaddleJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
pkg/controller.v1/pytorch/pytorchjob_controller.go
124: func (r *PyTorchJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
pkg/controller.v1/tensorflow/tfjob_controller.go
119: func (r *TFJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
pkg/controller.v1/xgboost/xgboostjob_controller.go
121: func (r *XGBoostJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
3. 总结
本文从源码的角度概述了 training-operator 主要的启动流程及启过程中关键函数/方法,力求在简练的基础上让大家能够了解必要的关键细节,并以 TFJob 为例详细说明了 Controller 启动过程中的主要逻辑,以加强大家对概念的理解。
类比 k8s 中的 controller-manager 来看, controller-manager 管理着 k8s 原生工作负载(如:deployment/rs/sts/job)的生命周期,training-operator 也可以成是各种训练任务的管控,负责管理不同训练任务控制器的生命周期。
大部分训练任务的控制器都会监控 &kubeflowv1.XXJob/pod/service 的事件,个别任务可能会有些许差异,例如:MPIJob,它不会订阅 service 相关的事件,而是会监听 &kubeflowv1.MPIJob/pod/cm/role/rolebinding/serviceaccount 相关的事件。