目录
1. 写在前面
本系列文章是对 kubeflow 中的
training-operator模块的代码解析, 基于以下代码:
git commit:ab5de23608c4f14a8629cc84d2be55cf2b251f37
通过系列文章中的第一篇我们对 training-operator 的主要逻辑有了较为清晰的了解,也明白了 training-operator 是如何通过 controller-runtime 与 k8s 进行交互的。
training-operator 作为 ML/DL 领域中一个平台大杂烩 kubeflow(好听一点: 平台技术栈)非常重要的一个组件,它以松耦合的方式运行在 kubeflow 中,用于支持不同训练模型/框架的运行。
需要注意:
- kubeflow 并不是真正意义上的 ML/DL 学习框架,自身也不具备调度能力(但可以使用 k8s 原生调度器,也可以使用 volcano 调度器)
- training-operator 是一个管理多控制器(即:不同训练框架的控制器)的 manager,不同的控制器共享同一个 manager 及 sharedInformer cache,这样做能减少不同控制器对 k8s API 访问的频次,减小 k8s API server 的压力。
- 对于机器学习任务来说,一般都是运行多个进程(ps/master 进程负责任务内的协调,worker 进程负责完成任务要干的事情),所有这些进程都是运行同一段代码,并且它们之间会共享一些全局信息,所以整体上不同的 operator(tf/pytorch/mpi 等)会有很多相似之处。
因为后面的分析会多少ieyi到TensorFlow 中的 cluster 是一组参与分布式执行计算的任务(Task)集合。每个任务都与一个 TensorFlow 的服务器(Server) 相关联,服务器中包含一个可以用来创建会话(sessions)的Master和一个在计算中完成具体命令的Worker。一个集群同样可以被分为一个或多个作业(Job),每个作业又包含一个或多个任务。
2. 实践 - 运行 tfJob
准备以下 yaml 文件,定义 tfJob 中的关键角色 PS/Worker,tfJob 中共支持 5 种类型,详情查询 ReplicaType。
apiVersion: kubeflow.org/v1
kind: TFJob
metadata:
name: dist-mnist-for-e2e-test
namespace: kubeflow
spec:
tfReplicaSpecs:
PS:
replicas: 1
restartPolicy: Never
template:
spec:
containers:
- image: kubeflow/tf-dist-mnist-test:v1-b938905
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
Worker:
replicas: 1
restartPolicy: Never
template:
spec:
containers:
- image: kubeflow/tf-dist-mnist-test:v1-b938905
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
部署并观察执行结果:
# 部署到 k8s 环境中
[ ][jeffrey] ﴱ kind-kind() ~/Documents [ 11GiB/16GiB | 2GiB/4GiB]
[00:17:37] ❯ k apply -f tf.yaml
# 查看部署结果,上述 yaml 部署后会先创建一个 tfJob, 然后拉起来两个 pod。
[ ][jeffrey] ﴱ kind-kind() ~/Documents/playwithk8s/calico [ main]( U) [羽 2m35s][ 12GiB/16GiB | 1GiB/2GiB]
[00:19:42] ❯ k get TFJob -n kubeflow
NAME STATE AGE
dist-mnist-for-e2e-test Succeeded 29m
[ ][jeffrey] ﴱ kind-kind() ~/Documents [ 11GiB/16GiB | 2GiB/4GiB]
[00:15:34] ❯ k get po -o wide -n kubeflow
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dist-mnist-for-e2e-test-ps-0 1/1 Running 0 6m25s 192.168.162.133 kind-worker <none> <none>
dist-mnist-for-e2e-test-worker-0 0/1 Completed 0 6m25s 192.168.162.134 kind-worker <none> <none>
# 查看 ps server 的执行日志
[ ][jeffrey] ﴱ kind-kind() ~/Documents [ 11GiB/16GiB | 2GiB/4GiB]
[00:18:30] ❯ k logs -f dist-mnist-for-e2e-test-ps-0 -n kubeflow
/usr/local/lib/python2.7/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
2024-01-02 09:12:30.527424: I tensorflow/core/platform/cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: SSE4.1 SSE4.2
2024-01-02 09:12:30.544305: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:2222}
2024-01-02 09:12:30.544338: I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> dist-mnist-for-e2e-test-worker-0.kubeflow.svc:2222}
2024-01-02 09:12:30.547114: I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:2222
tfJob controller 的其中一个作用是把 TF_CONFIG 写到每个 pod 中,TF_CONFIG 中指明了当前使用的 clusterSpec、节点类型及索引。如下:
# 登陆到 ps server 中查找 tfJob 控制器配置的环境变量
[ ][jeffrey] ﴱ kind-kind() ~/Documents [ 11GiB/16GiB | 2GiB/4GiB]
[00:26:05] ❯ k exec -it dist-mnist-for-e2e-test-ps-0 -n kubeflow /bin/sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
# env
KUBERNETES_SERVICE_PORT=443
KUBERNETES_PORT=tcp://10.96.0.1:443
TRAINING_OPERATOR_SERVICE_PORT=8080
TRAINING_OPERATOR_PORT=tcp://10.96.4.165:8080
TF_CONFIG={"cluster":{"ps":["dist-mnist-for-e2e-test-ps-0.kubeflow.svc:2222"],"worker":["dist-mnist-for-e2e-test-worker-0.kubeflow.svc:2222"]},"task":{"type":"ps","index":0},"environment":"cloud"}
HOSTNAME=dist-mnist-for-e2e-test-ps-0
TRAINING_OPERATOR_SERVICE_PORT_MONITORING_PORT=8080
HOME=/root
TRAINING_OPERATOR_PORT_8080_TCP=tcp://10.96.4.165:8080
TERM=xterm
KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
KUBERNETES_PORT_443_TCP_PORT=443
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_SERVICE_HOST=10.96.0.1
PWD=/notebooks
TRAINING_OPERATOR_PORT_8080_TCP_ADDR=10.96.4.165
TRAINING_OPERATOR_SERVICE_HOST=10.96.4.165
TRAINING_OPERATOR_PORT_8080_TCP_PORT=8080
TRAINING_OPERATOR_PORT_8080_TCP_PROTO=tcp
# worker 中配置的环境变量
- env:
- name: TF_CONFIG
value: '{"cluster":{"ps":["dist-mnist-for-e2e-test-ps-0.kubeflow.svc:2222"],"worker":["dist-mnist-for-e2e-test-worker-0.kubeflow.svc:2222"]},"task":{"type":"worker","index":0},"environment":"cloud"}'
image: kubeflow/tf-dist-mnist-test:v1-b938905
imagePullPolicy: IfNotPresent
name: tensorflow
ports:
- containerPort: 2222
name: tfjob-port
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-5s5bq
readOnly: true
从上面的结果看,要创建一个群集,我们需要群集中为每个任务启动一个 ps 服务器,通常每个任务运行在不同的机器上,然后在每个任务中都做如下操作:
- 创建
clusterSpec。在集群中创建一个描述所有任务的tf.train.ClusterSpec,它对每个任务而言都应该是相同的 - 创建
psServer。创建一个tf.train.Server,将tf.train.ClusterSpec传给构造函数,并用 job 名称标识本地任务和任务索引
从 k8s 侧来看,TFJob 是 k8s 中的一个 CR (custom resource,即 CRD 的一个实例),其定义位于pkg/apis/kubeflow.org/v1/tensorflow_types.go
// TFJob represents a TFJob resource.
type TFJob struct {
// Standard Kubernetes type metadata.
// 每一种 k8s 对象都会有这个字段,用于定义 k8s 对象的基础信息
metav1.TypeMeta `json:",inline"`
// +optional
metav1.ObjectMeta `json:"metadata,omitempty"`
// Specification of the desired state of the TFJob.
// +optional
Spec TFJobSpec `json:"spec,omitempty"`
// Most recently observed status of the TFJob.
// Populated by the system.
// Read-only.
// +optional
Status JobStatus `json:"status,omitempty"`
}
// TFJobSpec is a desired state description of the TFJob.
type TFJobSpec struct {
// 定义分布式任务的运行时策略,如:任务的最长运行时长、任务优雅停止时间、pod 清理策略、任务挂起策略等
RunPolicy RunPolicy `json:"runPolicy"`
// 定义如何判断 tfjob 是否运行成功
SuccessPolicy *SuccessPolicy `json:"successPolicy,omitempty"`
// A map of TFReplicaType (type) to ReplicaSpec (value). Specifies the TF cluster configuration.
// For example,
// {
// "PS": ReplicaSpec,
// "Worker": ReplicaSpec,
// }
// 基于此可以生成 tensorflow 中的 clusterSpec。tfjob 任务的一个关键点就是如何根据用户的输入,最终生成 clusterSpec
// https://www.tensorflow.org/api_docs/python/tf/train/ClusterSpec
TFReplicaSpecs map[ReplicaType]*ReplicaSpec `json:"tfReplicaSpecs"`
...
}
3. 源码分析
每一种训练任务都会有相应的XXXReconciler,对于 tfJob 同样会有一个 TFJobReconciler,定义位置 pkg/controller.v1/tensorflow/tfjob_controller.go。
// TFJobReconciler reconciles a TFJob object
type TFJobReconciler struct {
common.JobController // 每一种训练任务都会包含这个公共的 JobController
client.Client
Scheme *runtime.Scheme
apiReader client.Reader
...
}
从 training-operator 源码阅读系列之1 - 代码结构解析 中我们知道,每一种任务都会实现自己的 func Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) 方法,用于对当前状态进行调整以达到期望状态。
下面看一下 tfJob 中的 Reconcile 都做了啥。 首先获取并验证 tfJob 的合法性,检查通过后再判断是否需要进行调谐,即:根据当前状态与预期状态是否一致决定是否有必要后面的操作,如果一致,则直接退出无需调谐。如果二者不一致,会调用 JobController.ReconcileJobs 进行调谐,以达到实际状态与预期状态一致的目的。
每一种任务都会经历类似的过程,每一种任务类型的 Reconcile 中比较重要或特殊的逻辑都放在了 JobController.ReconcileJobs 中。具体流程图下:
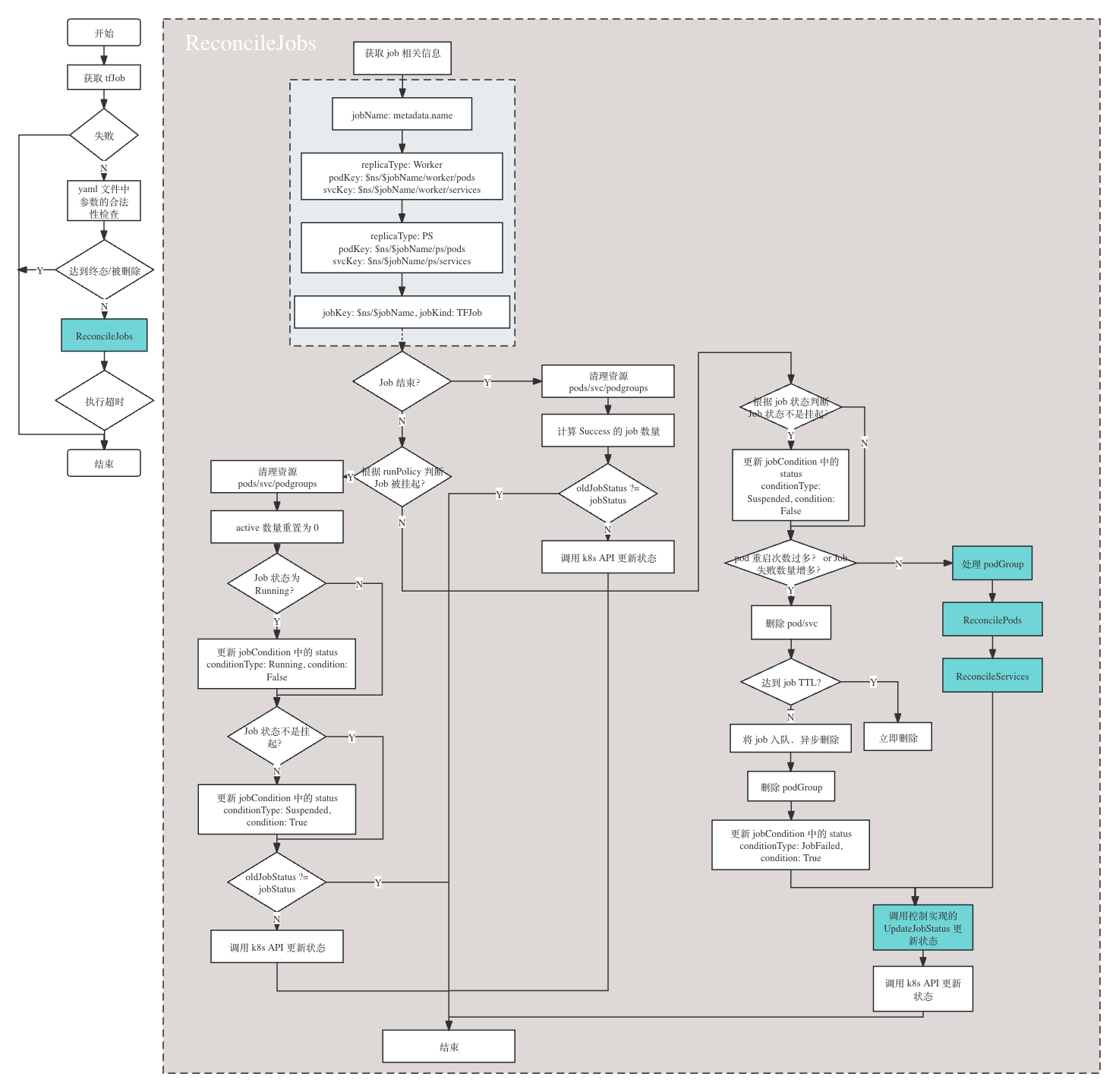
说明:
- 左侧流程图为 tfJob 的主流程
- 右侧流程图为 ReconcileJobs 中的详细流程
- 图中蓝色部分是需要重点关注的
- 最侧蓝色框图中的
处理 podGroup,ReconcilePods,ReconcileServices为通用方法,均在ControllerInterface中有所实现,代码位置:pkg/common/interface.goUpdateJobStatus不同的任务类型有不同的实现方式