目录
0. 背景和目标
背景
- 业界的需求
多租户的运行机制意味着不同类型的工作负载(如:deploy/sts/rs/crd等)或者团队可以共享同一套集群中的资源(如:节点、网络、存储、容器运行时等),并且工作负载与团队之间还需要实现资源的逻辑隔离或者物理隔离,在资源利用率要求较高的地方,甚至还会要求不同租户间打破隔离,实现按资源按规则(如:指定节点比例等)共享。
- 厂内的需求
当前用户区每申请一个智算环境,都需要创建一个孤立的 K8S 集群,K8S 集群运行所必须的控制面的服务需要同步部署。从用户角度来看,这些服务是无形的成本,这些节点通常不会用来部署用户的训推任务;从资源供应方来看,每个集群就相当于资源孤岛,不利于提高资源的售卖比,在多集群管理及资源池化方面也有不小的挑战。
目标
- 做什么:本文是针对 K8S 实现多租户方案的调研,目的是针对 K8S 平台,理清有哪些方案可以实现多租户,同时对友商多租户的实现方案做调研对比。
- 不做什么:K8S 多集群
1. 概述
企业组织在使用 K8S 时,为简化运维以及降低资源成本,通常组织内各个部门、团队需要共享使用 K8S 集群。
K8S 通过适当的配置,可以允许集群管理员创建一个共享基础设施,在其中多个租户可以在单个 K8S 环境中运行独立的工作负载,管理员根据租户的需求划分基础设施。
什么是租户? 租户可以简单理解为拥有一些资源(计算、网络、存储)、工作负载及用户/团队/组织的逻辑实体,租户管理员可以控制和管理集群的安全性和租户间的隔离性,用户可以共享底层集群的基础设施。
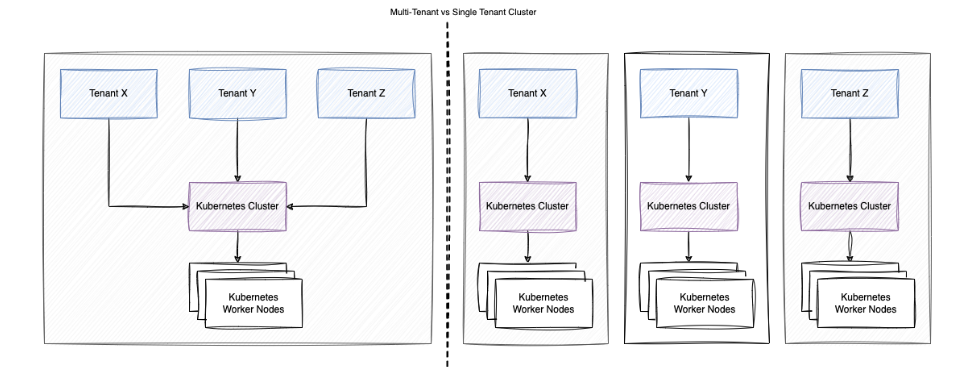
单多租户的区别?
二者对比请看下图:
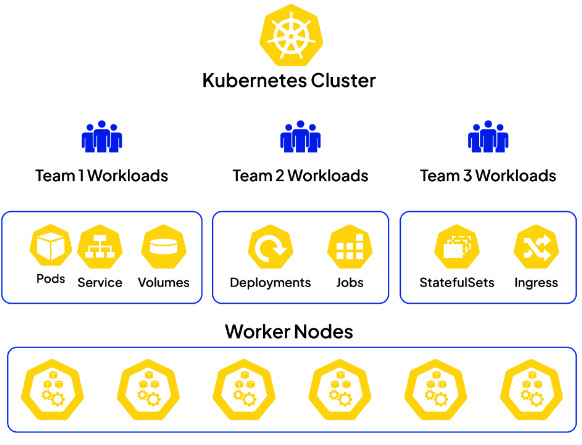
多租户的场景分类?
- 场景1:多团队租户(Multi-team tenancy)
- 情景: 具有多个团队聚焦在不同项目或应用的组织。
用例: 有效地利用少量集中管理的 K8S 集群,为各个团队提供各自隔离的环境。
- 场景2:多环境租户(Multi-environment tenancy)
- 情景: 应用或服务的开发、测试和生产阶段。
- 用例: 在共享的集群中创建灵活的分段、测试和生产环境。这通过允许开发人员在模拟生产设置的环境中工作,同时减少管理每个阶段的独立集群的开销,提高了开发人员的生产力。
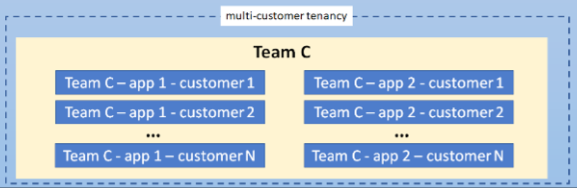
- 场景3:多客户租户(Multi-customer tenancy)
- 情景: 为多个客户提供软件即服务(SaaS)的提供商。
用例: SaaS 提供商通过共享的集群基础设施实现可伸缩性和成本节省。每个客户的数据和应用在相同的集群中被逻辑隔离,提供了效率和成本效益。
多租户使用场景示例
所有用户都来自企业,可以通过命名空间对不同部门或团队进行资源的逻辑隔离:
- 集群管理员:
- 具有集群的管理能力(扩缩容、添加节点等操作)
- 负责为租户管理员创建和分配命名空间
- 负责各类策略(RAM/RBAC/networkpolicy/quota…)的CRUD
- 租户管理员
- 至少具有集群的 RAM 只读权限
- 管理租户内相关人员的 RBAC 配置
- 租户内用户
- 在租户对应命名空间内使用权限范围内的k8s资源
2. K8S 隔离能力
根据 K8S 集群的架构可知,K8S 由控制平面(controller-manager/api-server/scheduler等)和数据平面(node等)组成, 租户工作负载最终以 Pod 的形式运行在各工作节点。
由此,多租户的实现可以从两个方面入手,即:
- 通过控制面实现
- 通过数据面实现
基于上述两个方面,设计和构建多租户的方案会有多种。每种方法都有自己的一组权衡,其中隔离性是首要考虑的事情,另外,基于不同程度的隔离实现,不同方案的工作量、操作复杂性和服务成本都会有差异。
下面从控制面和数据面出发,看一下 K8S 中如何实现不同程度的隔离。
2.1 基于控制面隔离
2.1.1 基于 Namespace 隔离
基于命名空间(namespace)的多租户是 K8S 中最简单的多租户实现方式。每个租户分配一个 namespace,租户内的资源都位于该 namespace 中,命名空间之间相互隔离,租户之间无法互相访问对方的资源,通过网络策略可以控制不同租户间的服务访问。
基于命名空间的多租户实现方案的优点是简单易用,不需要额外的配置或扩展。
同时缺点也是很明显的:
- 租户之间的资源隔离不够彻底。例如,租户内的 Pod 可以通过 Service 访问其他租户的资源。
- 租户的管理和控制权限不够灵活。例如,管理员无法为每个租户单独设置资源配额。
- 粒度划分的局限性比较大。例如,单个租户或应用团队再划分,这种细粒度级别几乎无法完成,这增加了管理难度。
- 隔离范围受限。例如:ds、storeageclass、pv 等这种属于集群范围的的资源不方便管理。
2.1.2 基于 RBAC 隔离
受 ns 控制,基于角色的多租户是 K8S 中功能最强大的多租户实现方案。基于角色的多租户使用角色来定义租户的权限,租户管理员可以通过角色来控制用户访问 K8S 集群中的资源。
基于角色的多租户实现方案的优点是原生支持,租户需要根据自己的需求来定义角色,并将角色授予用户,使用基于角色的访问控制(RBAC)来定义集群内每个用户和用户组的权限和角色,RBAC 可以帮助强制最小特权原则,并防止未经授权的操作或对集群资源的访问。
缺点是配置复杂,它不能防止人为错误或配置错误。
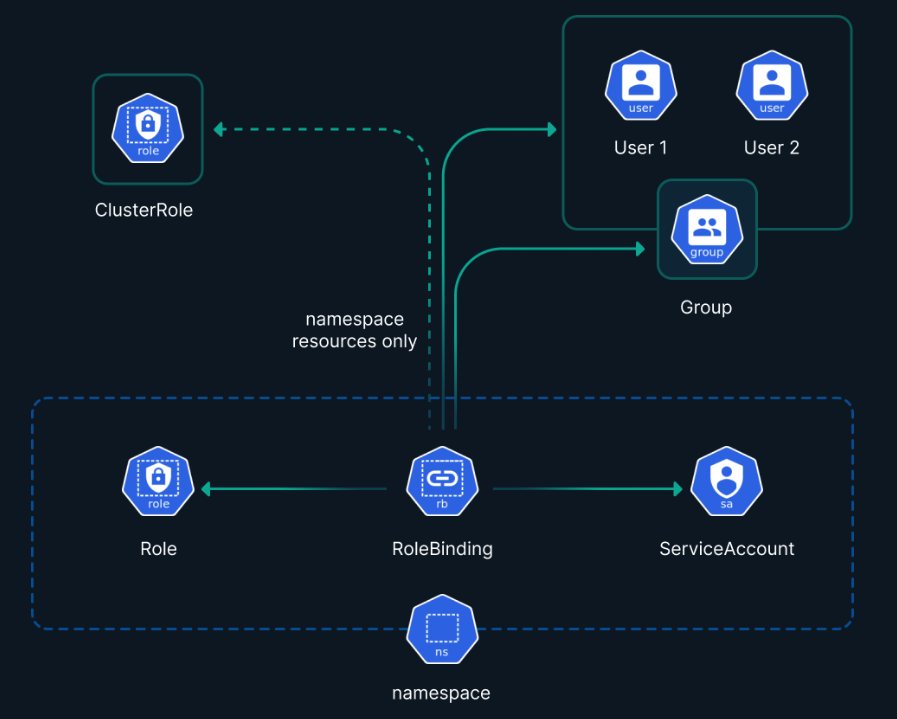
2.1.3 基于资源配额隔离
受 ns 控制,通过资源配额,可以限制每个命名空间或租户可以使用的资源量,如 CPU、内存、存储和其资源的数量等,这有助于防止单一个租户占用过多的集群资源,导致资源过度分配和集群资源的匮乏影响其他租户,另外,也可以开发 Operator,使用 CRD 定义自定义资源,以适应特定的多租户需求。例如,可以定义租户资源对象,并在其上应用 RBAC 规则和网络策略。
缺点是不能保证每个租户的性能或可用性。
2.1.4 基于虚拟控制面隔离
K8S SIG 提供了虚拟集群的概念,允许在同一物理集群中创建多个虚拟集群。这些虚拟集群可以被不同的租户拥有,每个租户提供单独的虚拟控制面,以便完全隔离租户的资源。虚拟控制面通常是通过为每个租户运行一组单独的 apiserver 来实现的,同时使用控制器将资源从租户 apiserver 同步到原有的 K8S 集群。
每个租户只能访问其相应的 apiserver,而原始 K8S 集群的 apiserver 通常不能从外部访问。虚拟控制面的完全隔离通常需要较高的资源消耗,但与数据面隔离技术结合使用,它是一个更彻底和安全的多租户解决方案。
针对虚拟集群,其中一个例子是 vcluster 项目,其架构如下:
它通过为每个租户提供一个虚拟控制面来实现租户之间的隔离,虚拟控制面通常由 K8S apiserver、控制器和 etcd 组成。
这种方案的优点是租户之间的隔离更加彻底,租户的管理和控制权限也更加灵活。但是,它也存在一些缺点,例如:
- 需要额外的配置和扩展,例如,需要为每个租户单独部署一个虚拟控制面。
- 成本更高,例如,需要额外的计算资源和存储资源。
2.2 基于数据面隔离
2.2.1 基于网络策略隔离
借助支持 NetworkPolicy 的 CNI 实现网络流量的隔离,有助于进一步隔离不同租户的网络流量,增强安全性;或者也可以使用 service mesh (istio/linkerd)提供的 7 层网络策略实现网络访问控制。
2.2.2 存储隔离
存储的隔离应保证 volume 不会跨租户访问。由于 StorageClass 是集群范围的资源,为防止 PV 被跨租户访问,应指定其 reclaimPolicy 为 Delete。此外,也应禁止使用例如 hostPath 这样的 volume,以避免节点的本地存储被滥用。
2.2.3 节点隔离
节点隔离可以使用将 Pod 指派给节点或 Virtual Kubelet 来实现。
使用多集群管理工具,可以将多个独立的 K8S 集群管理为一个整体。这种方法可以在不同的集群之间实现多租户隔离。
2.2.4 安全容器隔离
由于容器和宿主机共享内核,应用程序或者主机系统上的漏洞可能被攻击者所利用,从而突破容器边界而攻击到主机或者其他容器。解决方法通常是将容器放到一个隔离的环境中运行,例如虚拟机或者是用户态 kernel。前者以 Kata Containers 为代表,后者的代表则是 gVisor。
2.3 基于数据面和控制面隔离
从上面的讨论可以看出,共享 K8S 集群不是一件容易的事情,单纯的做数据面隔离或控制面隔离都是无法完全做的彻底隔离的;多租户不是 K8S 的内置特性,只能在其他项目的支持下在控制面和数据面上的租户隔离中实现,这为整个解决方案带来了相当大的学习和适应成本。因此,越来越多的用户转而采用多集群解决方案(关于多集群方案的实现,社区有专门的 SIG 讨论)。
常见的多集群方案有:
与集群共享解决方案相比,多集群解决方案有利有弊,优点是隔离程度高、边界清晰,缺点是开销和运维成本高。由于每个集群都需要独立的控制面和工作节点,K8S 集群通常构建在虚拟机上,以提高物理集群的利用率。然而,传统的虚拟化产品往往又大又重,因为它们需要处理广泛的场景。这使得它们过于昂贵,无法成为支持虚拟化Kubernetes集群的最佳选择。
3. 多租户实现方案
通过对多租户定义的理解及 K8S 隔离能力的分析,很明显的可以看出,为多租户共享 K8S 集群可以有以下几种方案:
- 基于虚拟化控制平面实现多租户
- 基于命名空间实现多租户
- 基于多集群实现多租户(不在这里讨论)
在进行方案选型时,要考虑以下几个方面
- 功能需求:
- 考虑租户是否需要访问完整集群以部署全局 K8S 对象,还是命名空间级别的隔离已经足够。
- 多集群/虚拟集群是可以让租户部署全局对象(如自定义资源定义(CRD))的合适解决方案,使其能够灵活地利用整个集群的功能而不影响其他租户,同时。
- 安全能力:
- 确定租户的工作负载是否会影响整个集群还是仅限于其命名空间。
- 多集群/虚拟集群提供比基于命名空间的方法更强大的隔离和安全边界,适用于部署集群范围资源的关键任务应用程序。
- 实现成本:
- 考虑每种多租户策略的成本、复杂性和运营开销。
- K8S 多租户实现方案的选择需要根据实际需求来决定。如果对隔离性要求不高,可以选择基于命名空间的多租户。如果对隔离性要求较高,可以选择基于角色的多租户。
3.1 每个租户独立的虚拟控制面
这种多租户模型会为每个租户提供专用虚拟控制面, 从而完全控制集群范围的资源和附加服务。 工作节点在所有租户之间共享,并由租户通常无法访问的 host 集群管理。 由于租户的控制面不直接与底层计算资源相关联,因此它被称为虚拟控制平面.
虚拟控制面/虚拟集群(VirtualCluster)它代表一种新的架构,用于解决各种 K8S 控制平面隔离挑战。它通过为每个租户提供一个集群视图来扩展现有基于命名空间的 K8S 多租户模型。vc 完全利用了 K8S 的可扩展性,并保持了完整的API兼容性。
使用 vc,每个租户被分配一个专用的租户控制平面,租户可以在租户控制平面中创建集群范围的资源,例如命名空间和 CRD,而不会影响其他租户。因此,由于共享一个 apiserver 而导致的大多数隔离问题消失了。实际管理物理节点的 K8S 集群被称为 host 集群,现在成为 Pod 资源提供者。
vc 由以下组件组成:
- vc-manager(虚拟集群管理器):引入了一个新的CRD(Custom Resource Definition)VirtualCluster,用于建模租户控制平面。vc-manager 管理每个 vc 自定义资源的生命周期。根据规范,它要么在本地K8s集群中创建 CAPN(Custom API Server Node)控制平面Pods,要么在提供有效 kubeconfig 的情况下导入现有的集群。
- syncer(同步器):一个中心化的控制器,从每个租户控制平面填充用于 Pod 提供的 API 对象到host 集群,并双向同步对象状态。它还定期扫描同步的对象,以确保租户控制平面和超级集群之间的状态一致。
- vn-agent(虚拟节点代理):一个节点守护程序,代理所有租户 kubelet API 请求到运行在节点上的 kubelet 进程。它确保每个租户只能访问本节点上的自己的 Pods。
通过这一思路实现的提供多租户的能力项目有
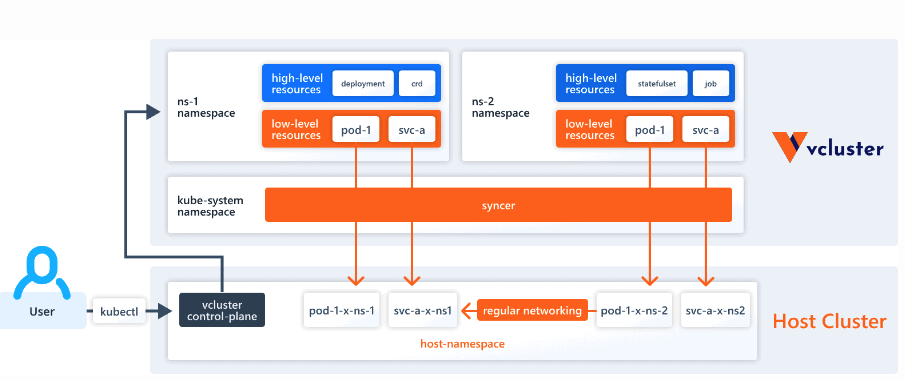
3.1.1 vcluster - 架构图
含义解析:
- 一个虚拟集群对应物理集群中一个命名空间
- 虚拟集群的控制面是通过物理集群的服务暴露的
- 虚拟集群通过 syncer 将指定类型的资源向物理集群做同步
- Service 与 Pod 的关系的绑定是在物理集群中做的,而非虚拟集群中
- 工作负载是否向物理集群做同步是有区分的
- 网络策略是在物理集群中实现
名词解释:
| 名称 | 解释 |
|---|---|
| Host Cluster | |
| 底层 K8S 物理集群,真正提供 node 节点等资源 | |
| host-namespace | host 集群中的命名空间,在不同的命名空间中运行着不同 vc 中创建的 pod/service 等工作负责和资源 |
| vcluster-control-plane | 虚拟控制平面,允许用户将 host 集群的一部分资源(例如CPU、内存和存储)分配给单个vc,可以在 vc 级别实施访问策略、资源配额、k8s 版本、ingress 等,确保只有授权用户才能访问 |
| High-Level = Purely Virtual | 所有由 vc 创建的资源对象(如:deployment, sts, rs, crd 等)都只存储在 vc 侧 |
| Low-Level = Sync’d Resources | 需要同步给物理集群的资源 |
| syncer | 完成资源从虚拟集群同步到物理集群 |
3.1.2 vcluster - Demo
- 创建 vcluster

- 切换到 vc 并部署 volcano 及 普通 deployment
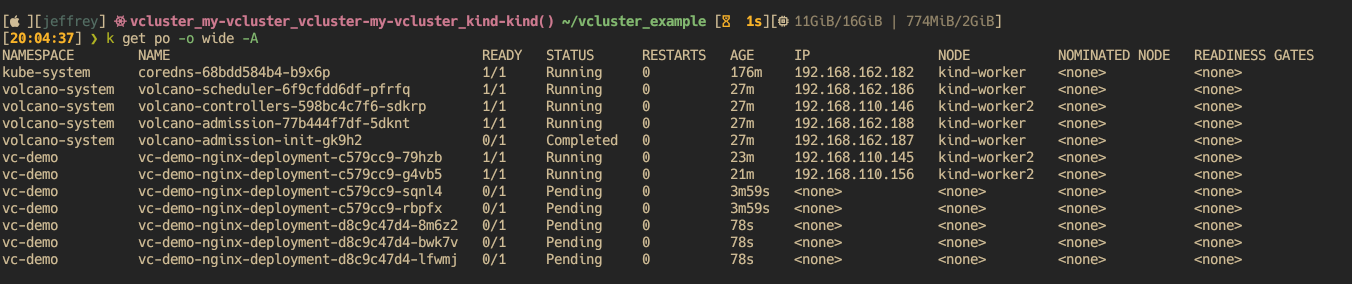

- vc 中创建的 ns

- 对配置了 ResourceQuota 的 vc, 验证超 quota 后的结果

- 切换到 host 集群并查看工作负载
可以看到虚拟集群中的资源同步到物理集群后的对应关系
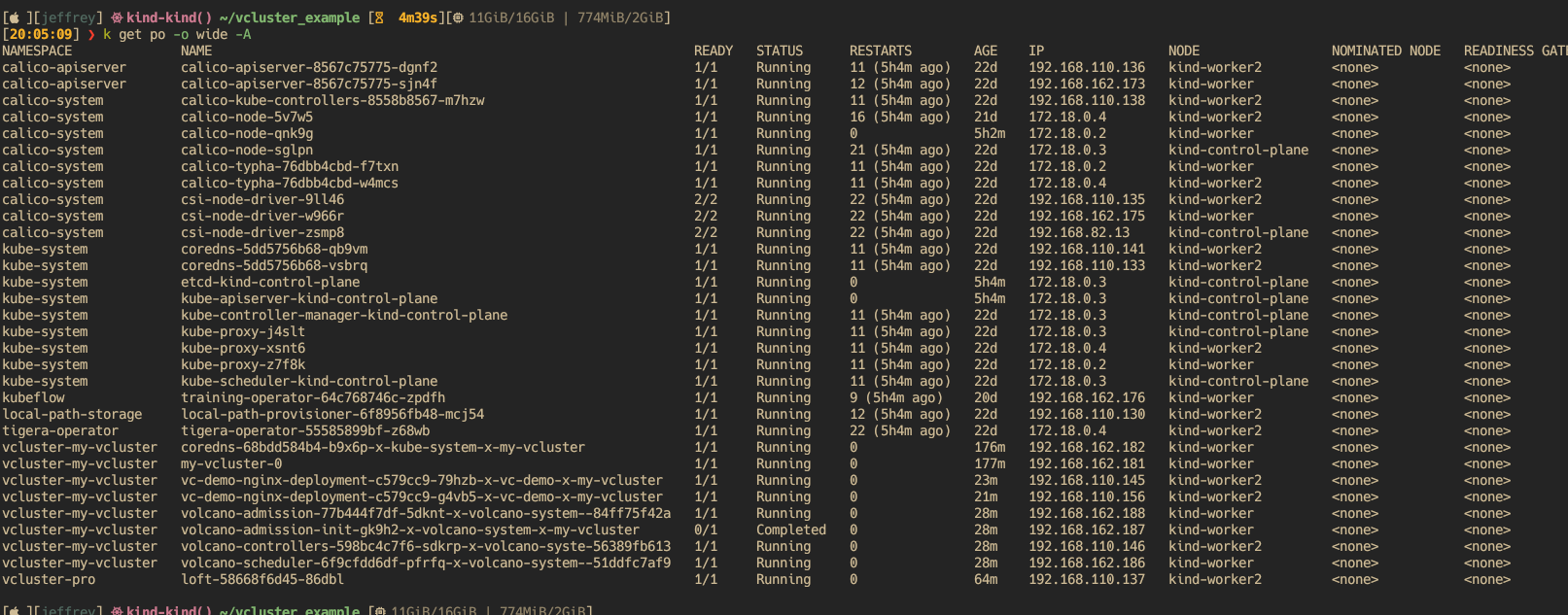
3.1.3 vcluster - 工作原理
从上面的实验中可以看出,一个 vcluster 实际上只有一个 coredns + statefulset。其中 statefulset 实际上是启动了两个容器:一个容器中运行 k3s 服务,另一个容器中运行了 syncer(即图中中间部分)。
Init Containers:
vcluster:
Image: rancher/k3s:v1.28.2-k3s1
Command:
/bin/sh
Args:
-c
cp /bin/k3s /k3s-binary/k3s
Containers:
syncer:
Image: ghcr.io/loft-sh/vcluster:0.18.1
这两个容器中,K3S 是与 K8S 完全兼容的简化的发行版,这里启动的 K3S 是一个裁剪版的 K3S, 诸如网络策略、调度的能力是没有启动的,在虚拟集群中创建的 pod 信息会通过 syncer 同步到物理集群中,在同步过程中,虚拟集群中创建的资源(如 pod)名称同步到物理集群时会被重写,即 vcluster 中的资源与物理集群中的资源是有映射关系的;pod 的调度是会交还到物理集群中去完成的。
存在的问题:由于网络是透传的,如果有些资源中是通过注解去做资源绑定时,在虚拟集群中创建的资源,是可以使用到物理集群中的一些服务的; 无法在 vcluster 中指定端口号使用 NodePort。
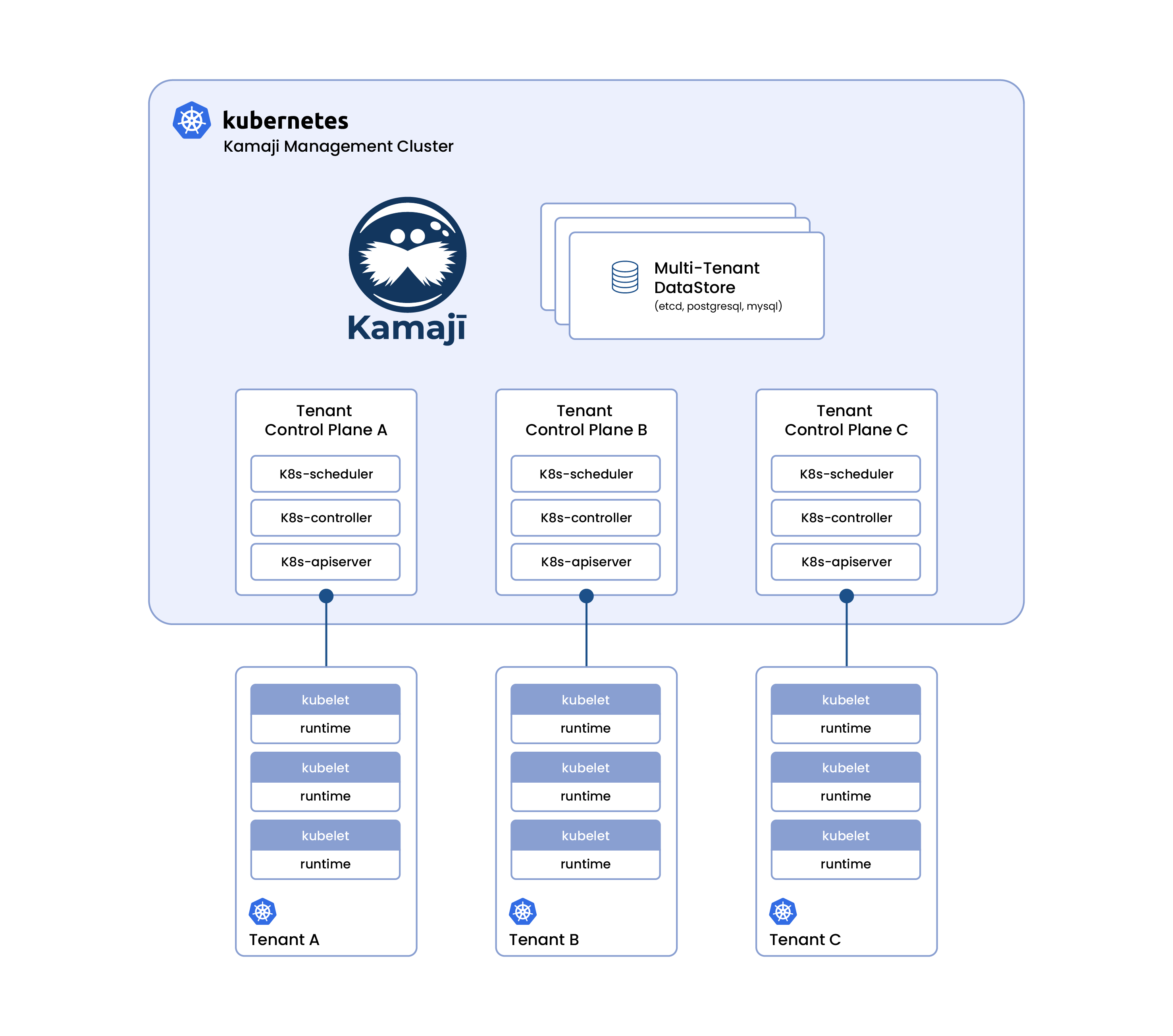
3.1.4 不同方案对比
| 方案 | 社区活跃度 | 资源消耗 | 灵活性 | 支持的规模 | 部署形式 | 隔离性 | 高可用 | 文档支持 | 调度器 | pv/storageclass | API 兼容性 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 【推荐】vcluster | 高(3.8k star) | 小 | 高 | - | pod | 弱/软 | 支持 | 高 | 共用或独占 | 管理集群提供 | 高 |
| kamaji | 低(600+ star) | 大 | 低 | 100 个租户完成同步需要 7m30s. https://kamaji.clastix.io/reference/benchmark/ | pod | 强/硬 | 支持 | 低 | 独占 | 虚拟集群提供 | 高 |
3.2 每个租户独立的命名空间
需要考虑的问题:
- 层级组织与层级配额管理
- 父子层级间策略的继承
使用命名空间实现多租户有两种思路:
- 思路1: namespace + operator + ResourceQuota + kyverno
我们知道,K8S 原生的 namespace 是一种扁平的资源隔离手段,如果它具备分层能力,那就会比较容易组织成分成层的结构,定义父子命名空间,并在父子命名空间中复制资源。例如:把不同的命名空间组织成层次结构,并在不同 namespace 之间共享某些策略和资源。分层和隔离能力具备后,我们就可以开发自己 operator 用于管理命名空间生命周期和委托管理,并在相关命名空间之间共享资源配额,开源实现有 hnc/capsule/volcano 等。
- 思路2: 协议转换
对租户的请求进行协议转换,使得每个租户看到的都是独占的 K8S 集群。对于后端集群来说,多个租户实际上是利用了 namespace 的原生隔离性机制而共享了同一个集群的资源, 这种较轻量的开源实现有 kubezoo。
3.2.1 Hierarchical Namespace Controller (HNC)
除了对命令空间有分层外,还支持对资源分层(hrq)
**[ ][jeffrey] ﴱ kind-kind() ~/vcluster_example [ 13GiB/16GiB]
[14:15:35] ❯ k api-resources | grep hnc
61: hierarchicalresourcequotas hrq hnc.x-k8s.io/v1alpha2 true HierarchicalResourceQuota
62: hierarchyconfigurations hnc.x-k8s.io/v1alpha2 true HierarchyConfiguration
63: hncconfigurations hnc.x-k8s.io/v1alpha2 false HNCConfiguration
64: subnamespaceanchors subns hnc.x-k8s.io/v1alpha2 true SubnamespaceAnchor
[ ][jeffrey] ﴱ kind-kind() ~/vcluster_example [ 13GiB/16GiB]
[14:16:25] ❯ k get all -n hnc-system
NAME READY STATUS RESTARTS AGE
pod/hnc-controller-manager-84cbc6d6b6-vvsdv 1/1 Running 1 (17m ago) 29m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/hnc-controller-manager-metrics-service ClusterIP 10.96.155.237 <none> 8080/TCP 29m
service/hnc-webhook-service ClusterIP 10.96.143.11 <none> 443/TCP 29m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/hnc-controller-manager 1/1 1 1 29m
NAME DESIRED CURRENT READY AGE
replicaset.apps/hnc-controller-manager-84cbc6d6b6 1 1 1 29m**
3.2.2 Capsule
https://github.com/clastix/capsule
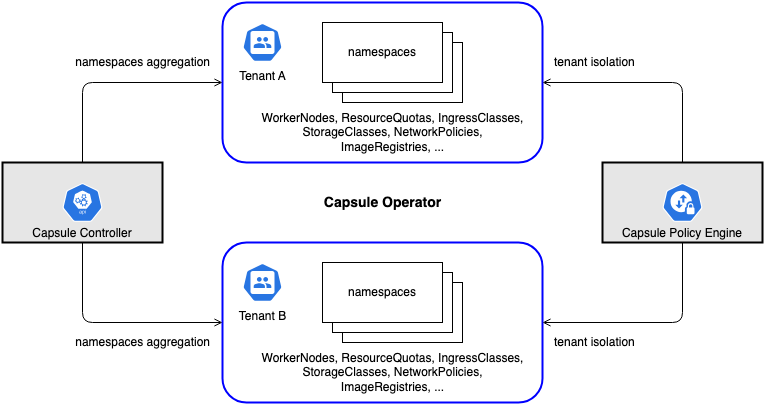
与 HNC 思路类似,它是基于 HNC,在上层抽象出了 Tenant 的 CRD,Tentant 是多个命名空间的集合,用一个 Tenant 中,用户可以任意创建 ns 和其它资源;另外,他有一个集中式的策略引擎,用于保证每个 Tenant 都会各自的网络策略、安全策略、ResourceQuota 等。
架构图
kubectl apply -f - << EOF
apiVersion: capsule.clastix.io/v1beta2
kind: Tenant
metadata:
name: oil
spec:
owners:
- name: alice
kind: User
namespaceOptions:
quota: 3
resourceQuotas:
scope: Tenant
items:
- hard:
limits.cpu: "8"
limits.memory: 16Gi
requests.cpu: "8"
requests.memory: 16Gi
- hard:
pods: "10"
limitRanges:
items:
- limits:
- default:
cpu: 500m
memory: 512Mi
defaultRequest:
cpu: 100m
memory: 10Mi
type: Container
EOF
3.2.3 Kiosk
https://github.com/loft-sh/kiosk
多租户扩展项目,在控制面和数据平面上实现租户隔离来实现多租户。
在控制面上,kiosk 使用 RBAC 来限制租户对 K8S 资源的访问。每个租户都有一个独立的 RBAC 策略,该策略定义了该租户可以创建和管理的资源类型和权限;在数据平面上,kiosk 使用容器网络隔离来隔离不同租户的 Pod。每个租户都有一个独立的网络命名空间,该命名空间中的 Pod 只能与同一租户中的 Pod 通信。
架构图
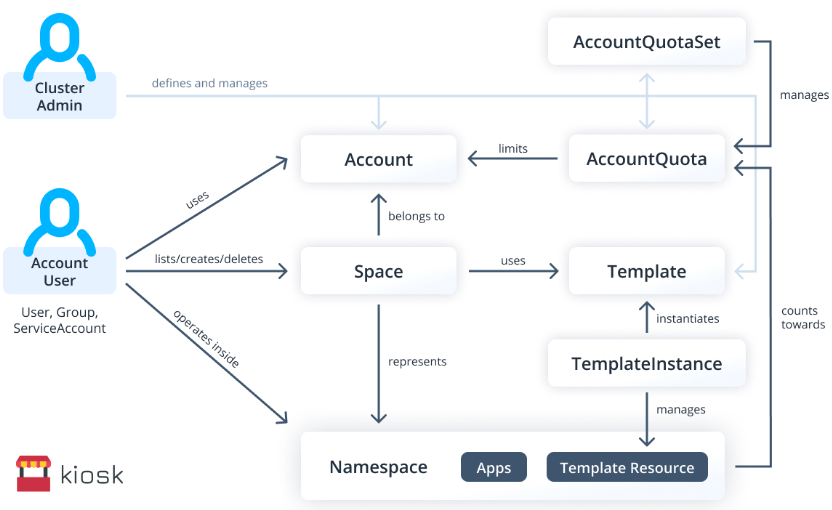
功能主要分为三部分:一块是和 account (即租户)相关的。另一个部署是 quota。第三部分模板。space 从属于 account,与原生的 ns 为 1:1 关系。
工作原理

分为三层,最下面是标准 k8s API
3.2.4 KubeZoo
KaaS 或 CPaasS 的隔离方案引入了过多的额外开销,比如每个租户需要建立独立的控制面组件,这样就降低了资源利用率;同时大量租户集群的建立,也会带来运维方面的负担。
另外,无论是公有云还是私有云,都存在大量小租户并存的场景。在这些场景下,每个租户的资源需求量比较小,同时租户又希望在创建集群之后,能够立即使用集群。
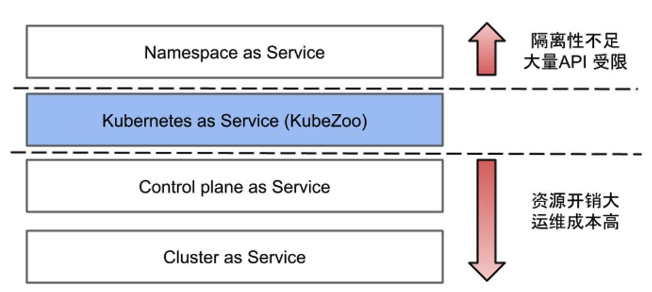
针对这种海量小租户并存的场景,我们就提出了一种轻量级的多租户方案——KubeZoo。它本质是作为一个网关服务,部署在 API Server 的前端。它会抓取所有来自租户的 API 请求,然后注入租户的相关信息,最后把请求转发给 API Server,同时也会处理 API Server 的响应,把响应再返回给租户。
3.2.5 不同方案对比
| 方案 | 隔离性 | 运维成本 | 资源利用率 | API 兼容性 | 集群创建效率 | 高可用 | 调度器 |
|---|---|---|---|---|---|---|---|
| HNC | |||||||
| capsule | |||||||
| kiosk | |||||||
| kubezoo |
3.3 其它方案
3.3.1 基于 volcano 队列实现多租户
3.4 不同实现方案的对比
| 方案 | 实现方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 【推荐】虚拟集群 | vcluster | 独立性高 | 管理相对复杂 | 大规模、需要高度隔离的多租户需求 |
| 命名空间隔离 | HNC | 简单易用 | 灵活性相对较低 | 小型、简单的多租户需求 |
| RBAC 和网络策略 | — | 灵活,细粒度控制 | 管理复杂 | 中等规模、复杂的多租户需求 |
| 多集群管理 | kamada | 硬隔离 | 部署和管理复杂 | 多集群、跨地域管理的多租户需求 |
4. 参考
- TKE 多租户实现
- selos 多租户实现
- kubesphere多租户实现
- https://learn.microsoft.com/en-us/azure/aks/operator-best-practices-cluster-isolation
- https://itnext.io/multi-tenancy-in-kubernetes-332ff88d55d8
- https://developer.volcengine.com/articles/7083791788158222349
- https://loft.sh/
- https://www.cncf.io/blog/2022/11/09/multi-tenancy-in-kubernetes-implementation-and-optimization/
- https://github.com/kubernetes-sigs/cluster-api-provider-nested/blob/main/virtualcluster/doc/vc-icdcs.pdf
- https://kubesphere.io/zh/docs/v3.4/access-control-and-account-management/multi-tenancy-in-kubesphere/
- https://zhuanlan.zhihu.com/p/583437805
- https://github.com/kubernetes/community/blob/master/sig-multicluster/README.md
- https://cloud.google.com/kubernetes-engine/docs/concepts/multitenancy-overview?hl=en
- https://izsk.me/2023/07/22/Kubernetes-multi-tenancy/
- https://www.linkedin.com/pulse/multi-tenancy-kubernetes-in-depth-analysis-cristofolini/
- https://loft.sh/blog/10-essentials-for-kubernetes-multi-tenancy/
- https://www.cncf.io/blog/2019/06/20/virtual-cluster-extending-namespace-based-multi-tenancy-with-a-cluster-view/