目录
- 1. 嵌入(Embedding)的作用
- 2.
emb_size的具体含义 - 3.
emb_size在模型架构中的角色 - 4. 影响
emb_size选择的因素 - 5. 与其他嵌入类型的结合
- 6. 实际应用中的注意事项
- 7. 示例代码(PyTorch)
- 8. 总结
在大型语言模型(LLM)中,emb_size 是 Embedding Size(嵌入维度)的缩写,表示模型中将离散符号(如词、标记等)映射到连续向量空间的维度大小。
举个例子来说明: 假设我们有一句话:"Hello world"
模型首先会把这两个词分词成两个 token:
- “Hello”
- ” world”
然后模型会把这两个 token 映射为两个向量(向量是数值的集合,用来表示这个 token 的语义)。
如果模型的 emb_size = 768,那这两个 token 会被映射成:
Hello → [0.12, -0.35, ..., 1.05](共 768 个数字)world → [0.89, -0.27, ..., -0.54](共 768 个数字)
这里的 768 就是 embedding 的维度大小,表示每个 token 被表示成一个 768 维的向量。
emb_size 越大,理论上表示能力越强,因为可以容纳更多语义信息,但同时,计算成本也越高(内存和速度都会受影响)。
常见的 emb_size 数值:
- GPT-2 小模型:
emb_size = 768 - GPT-2 大模型:
emb_size = 1600 - GPT-3(175B):
emb_size = 12288
以下是关键点解析:
1. 嵌入(Embedding)的作用
- 在自然语言处理(NLP)中,嵌入层将输入的离散符号(如单词、子词或标记)转换为连续的向量表示。例如,词汇表中的每个词会被映射为一个
emb_size维的向量。 - 这些向量能够捕捉语义和语法信息,使得模型可以通过数学运算(如向量加减)处理语言关系(如“国王 - 男人 + 女人 ≈ 女王”)。
2. emb_size 的具体含义
- 维度大小:
emb_size定义了嵌入向量的长度。例如,若emb_size=768,则每个词会被表示为 768 维的浮点数向量。 - 参数规模:嵌入层是模型中参数最多的部分之一。若词汇表大小为
V,则嵌入层的参数量为V × emb_size(例如,50,000词表 +768维嵌入 ≈ 3,840 万参数)。
3. emb_size 在模型架构中的角色
- 输入层:嵌入层通常是模型的第一层,将输入标记(Token)转换为向量。
- 与其他层的关联:
- 在 Transformer 架构中,
emb_size通常与注意力层的隐藏维度(hidden_size)一致,避免维度不匹配。 - 若需要调整维度(如降维或升维),会通过线性投影层(如
nn.Linear)实现。
- 在 Transformer 架构中,
4. 影响 emb_size 选择的因素
- 模型容量:更大的
emb_size能编码更多信息,但会增加计算成本和内存占用。 - 任务需求:复杂任务(如机器翻译)可能需要更大的嵌入维度,而简单任务(如文本分类)可能用小维度。
- 经验设定:主流模型的常见选择:
- BERT-base:
emb_size=768 - GPT-3:
emb_size=12288(部分版本) - T5:
emb_size=768或1024
- BERT-base:
5. 与其他嵌入类型的结合
- 位置嵌入(Positional Embedding):在 Transformer 中,位置信息通过位置嵌入(与词嵌入相加)注入模型。其维度通常与
emb_size相同。 - 特殊标记嵌入:如
[CLS]、[SEP]等标记的嵌入也共享emb_size维度。
6. 实际应用中的注意事项
- 预训练模型适配:使用预训练模型(如 BERT、GPT)时,输入的嵌入维度必须与模型的
emb_size匹配,否则会报错。 - 资源权衡:增大
emb_size会显著增加模型参数量,需根据硬件条件调整。
7. 示例代码(PyTorch)
import torch.nn as nn
import torch
vocab_size = 50000 # 词汇表大小
emb_size = 3 # 嵌入维度
# 定义嵌入层
embedding_layer = nn.Embedding(num_embeddings=vocab_size, embedding_dim=emb_size)
# 输入: [batch_size, seq_len]
input_ids = torch.LongTensor([[1, 23, 456, 7890]])
print(input_ids)
# 输出: [batch_size, seq_len, emb_size]
embedded_vectors = embedding_layer(input_ids)
print(embedded_vectors)
输出:
tensor([[ 1, 23, 456, 7890]])
tensor([[[-1.3028, 1.1171, -0.0110],
[-0.6384, -0.1001, -0.7859],
[-0.6411, 0.5972, 0.6548],
[-0.8056, 0.0659, -0.1239]]], grad_fn=<EmbeddingBackward0>)
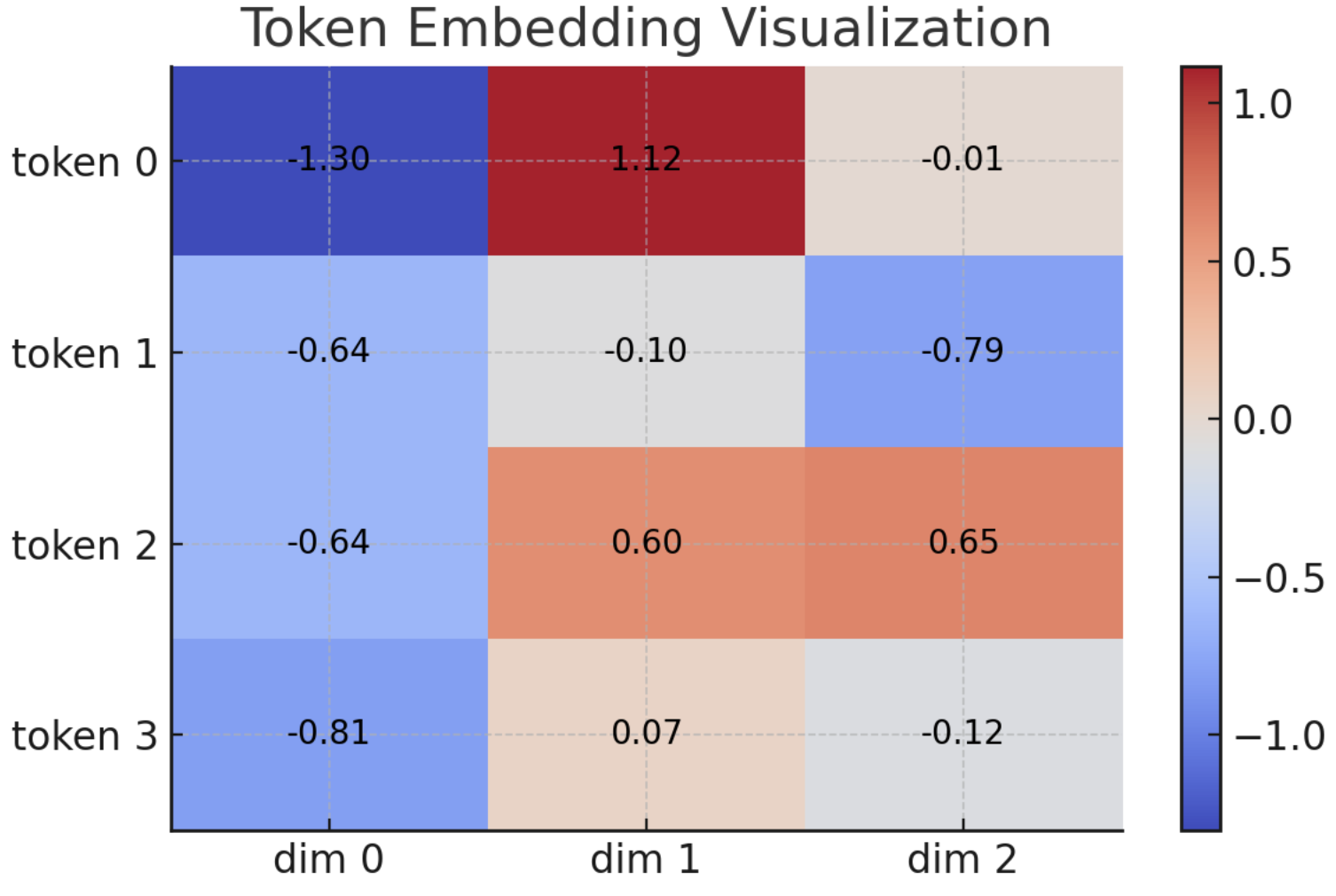
这个图展示了一个形状为 4 x 3 的嵌入向量矩阵,其中:
- 每一行代表一个 token 的嵌入表示
- 每一列是该 token 嵌入向量中的某个维度
- 色彩表示值的大小,红表示较高的值,蓝表示较低的值
- 每个格子中还标注了具体的数值,便于查看
8. 总结
emb_size 是 LLM 中决定嵌入向量维度的关键超参数,直接影响模型的表达能力、计算效率和内存占用。合理选择需权衡任务需求、模型复杂度和硬件资源。